Tutorials
– Collecting messages from Telegram using Telegram’s API and Python
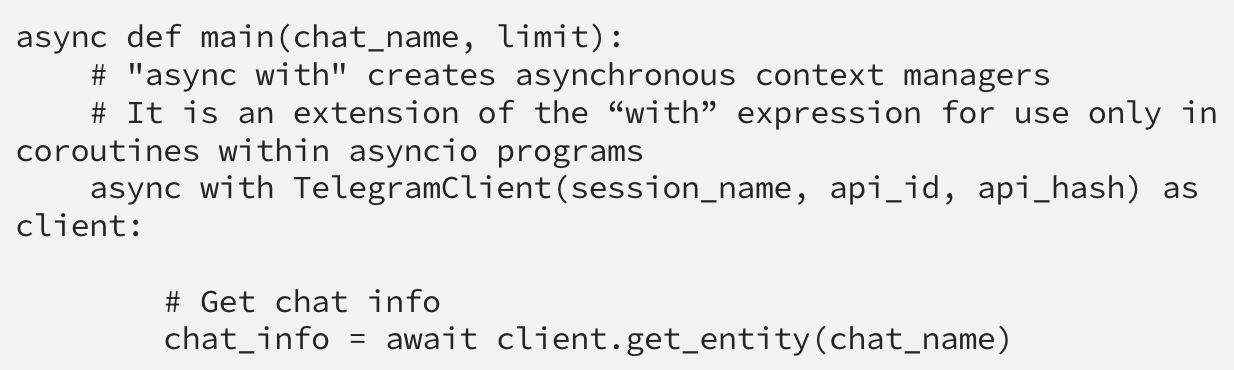
This tutorial illustrates how to use the Telethon library in Python to collect messages from any public channel or group chat on Telegram. It covers basics of concurrent and asynchronous programming, required for utilizing the Telethon package effectively. The tutorial also shows how to extract and save the retrieved responses and employs k-means clustering to analyze topics discussed in the posts collected from the official channel of the New York Times.
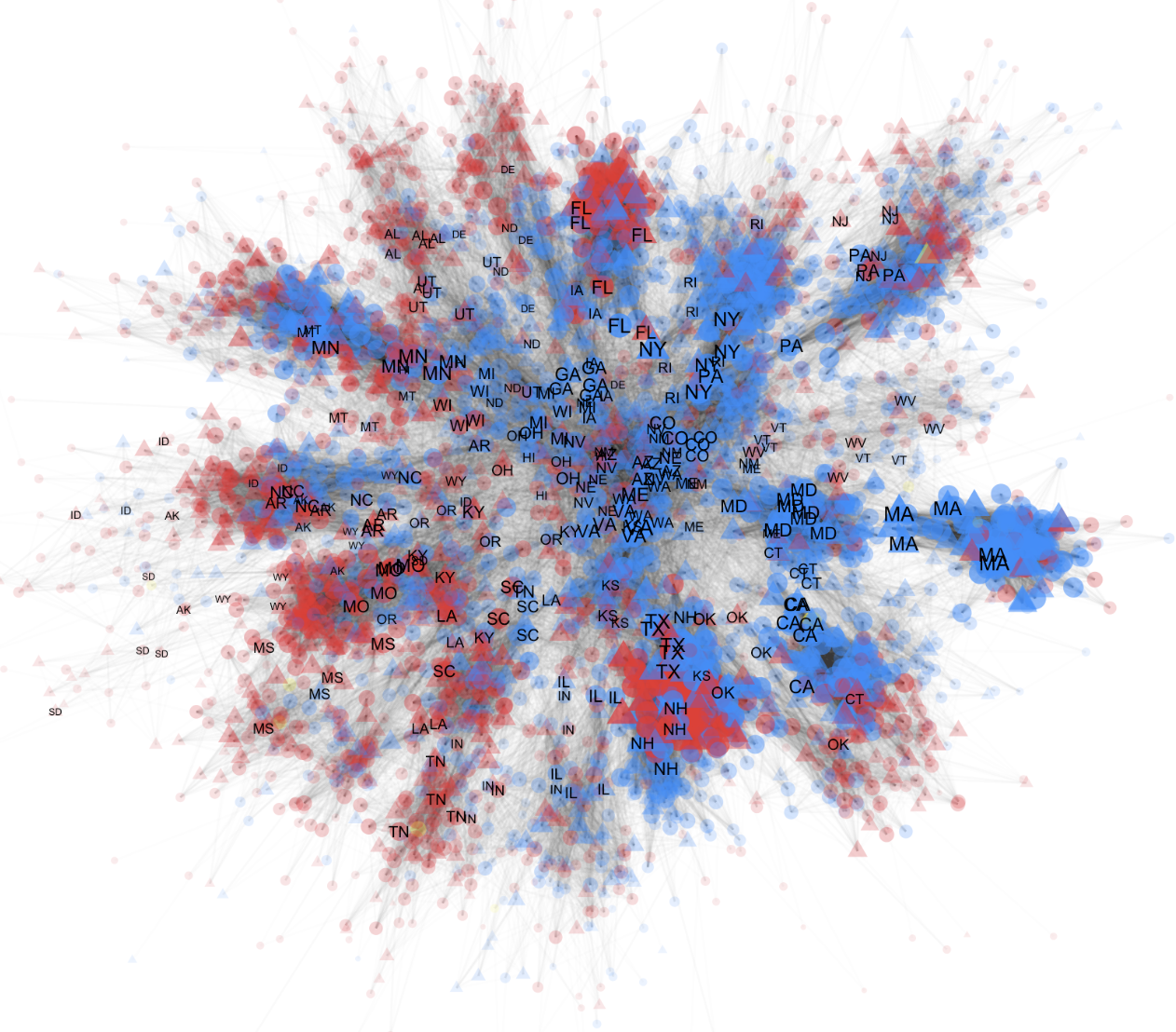
– Creating Network Visualizations Using tidygraph And ggraph
This tutorial shows how to use tidygraph, and ggraph libraries in R to create informative and ‘pretty’ network visualizations. I visualize the Twitter follower-followee connections among 4000+ state legislators in the US, comprising ~160,000 ties.
– Evaluating Zero-Shot Learning for Political Advertisement Classification
In this tutorial, I evaluate the performance of zero-shot learning for classification tasks using Facebook’s BART model to identify “Attack” and “Promote” ads. Unlike traditional classification models, zero-shot models do not require any training data. I implement these models with the transformers library, experiment with prompts to improve performance and evaluate the model on an expert labeled dataset of 10,000 advertisements.
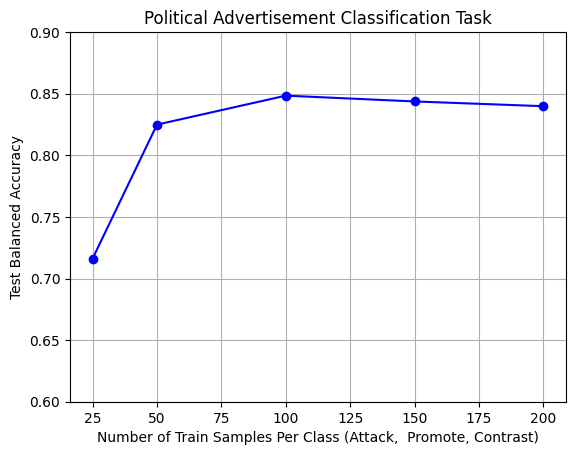
– Few Shot Text Classification with SetFit In this post, I evaluated Few Shot Learning using SetFit to classify political advertisements into: “promote,” “attack,” and “contrast” ads. I fine-tuned sentence embedding model and the classifier with just 100 samples per class, achieving an impressive balanced accuracy of 85%. The findings highlight the effectiveness of Few Shot Learning in delivering high classification performance with limited labeled data!
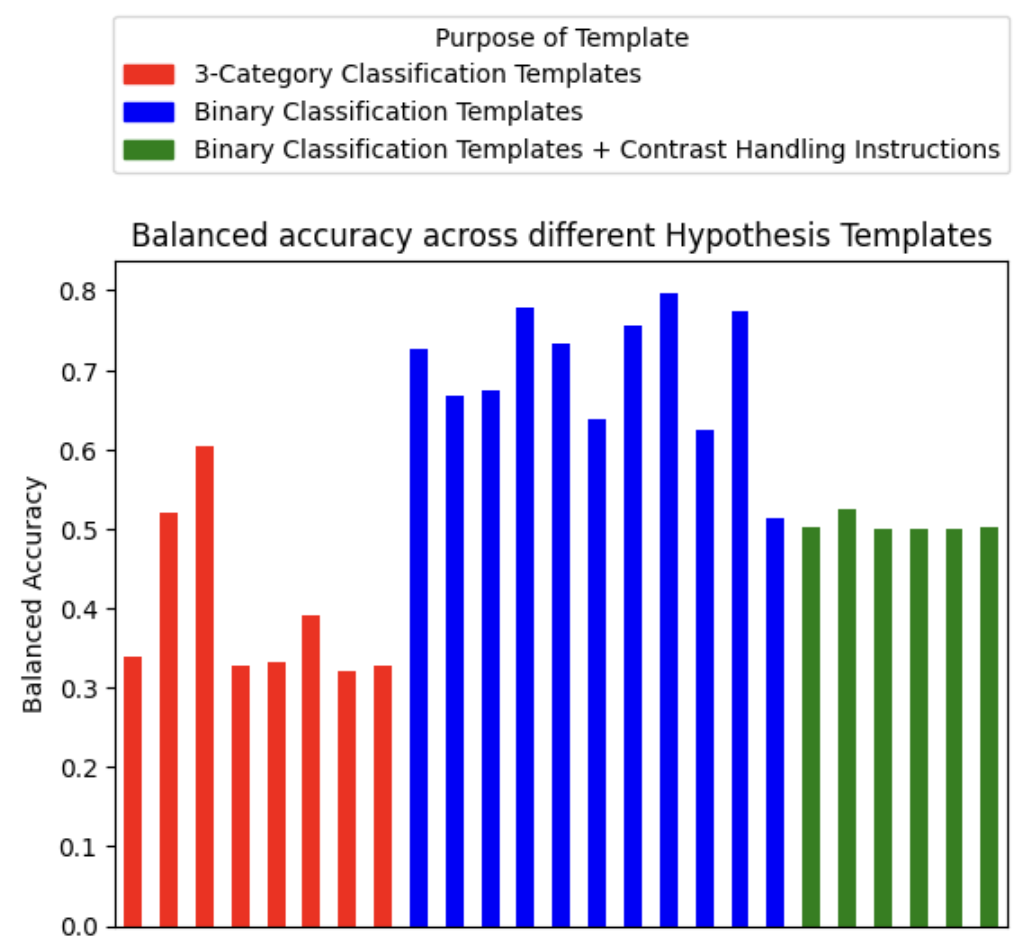
– Zero-shot Text Classification with SetFit Although SetFit is primarily designed for few-shot learning, it can be adapted for situations where no labeled data is available by generating “synthetic examples” that mimic the target classification task. This approach enables training the model on artificially created data. In this post, I evaluate SetFit’s performance on an advertisement classification task. I walk through the steps, which involve creating synthetic examples using 20+ templates, training the model, and evaluating the results.
– Text Classification in Python